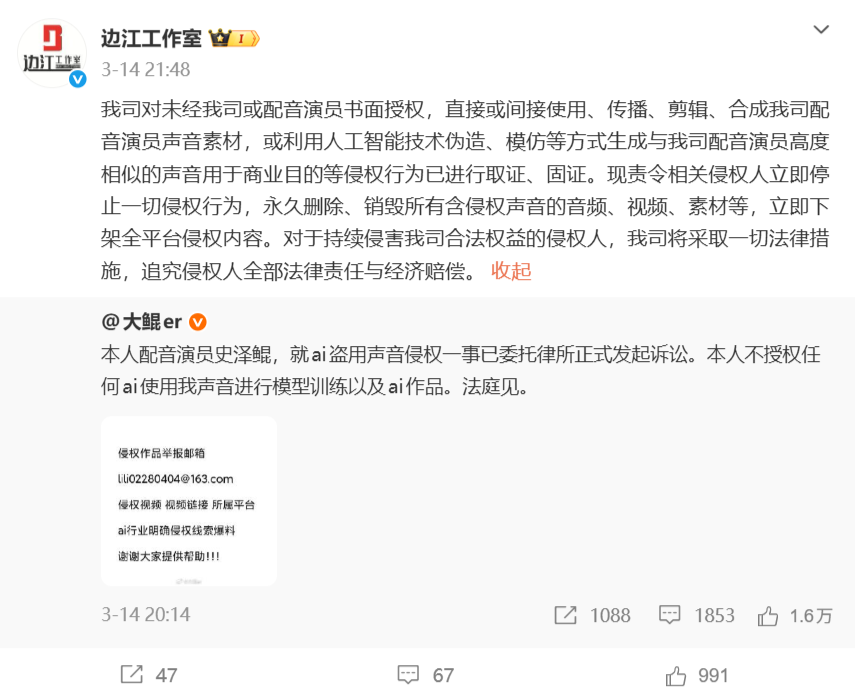
结构性的困境
配音演员们并非第一次面对声音被“克隆”的问题。
在AI大范围应用之前,行业内已经有一种被称为TTS(Text To Speech)的技术,需要人为去录制一些素材。
“它是专人选拔,付费授权。”言一回忆。一些地图导航类APP、短视频中的背景音,都是TTS的应用。
一家TTS语音制作公司的负责人告诉新京报记者,在他们的项目里,每一个声音都经过了配音演员的许可。她回忆,TTS行业早期也曾“不太规矩”。“一开始签协议有点霸王条款,跟你说我这有转授权,你要签就签,不签就这么着。”但随着行业发展,现在“大家都比较规矩了”。
许多配音演员认同这样的规范,但当前狂奔不止的技术给他们带来了更多考验。
在北京中勤律师事务所律师任相雨律师看来,这种困境是结构性的。
他曾代理过全国首例AI生成声音人格权侵权案。2023年,配音演员殷女士发现自己的声音被一款AI软件合成并商业化使用,最终起诉至法院。在这个案例中,任相雨就面临极大的取证困难。
“我们要根据声音来溯源它最开始从哪流出来的。”任相雨解释,殷女士案中,他们花了大量时间确定侵权主体——声音最初从哪个平台流出,平台与哪家公司合作,这家公司又从何处拿到声音样本。
最终,殷女士案胜诉。法院认定AI生成的声音如果具有“可识别性”,就受声音权益保护。
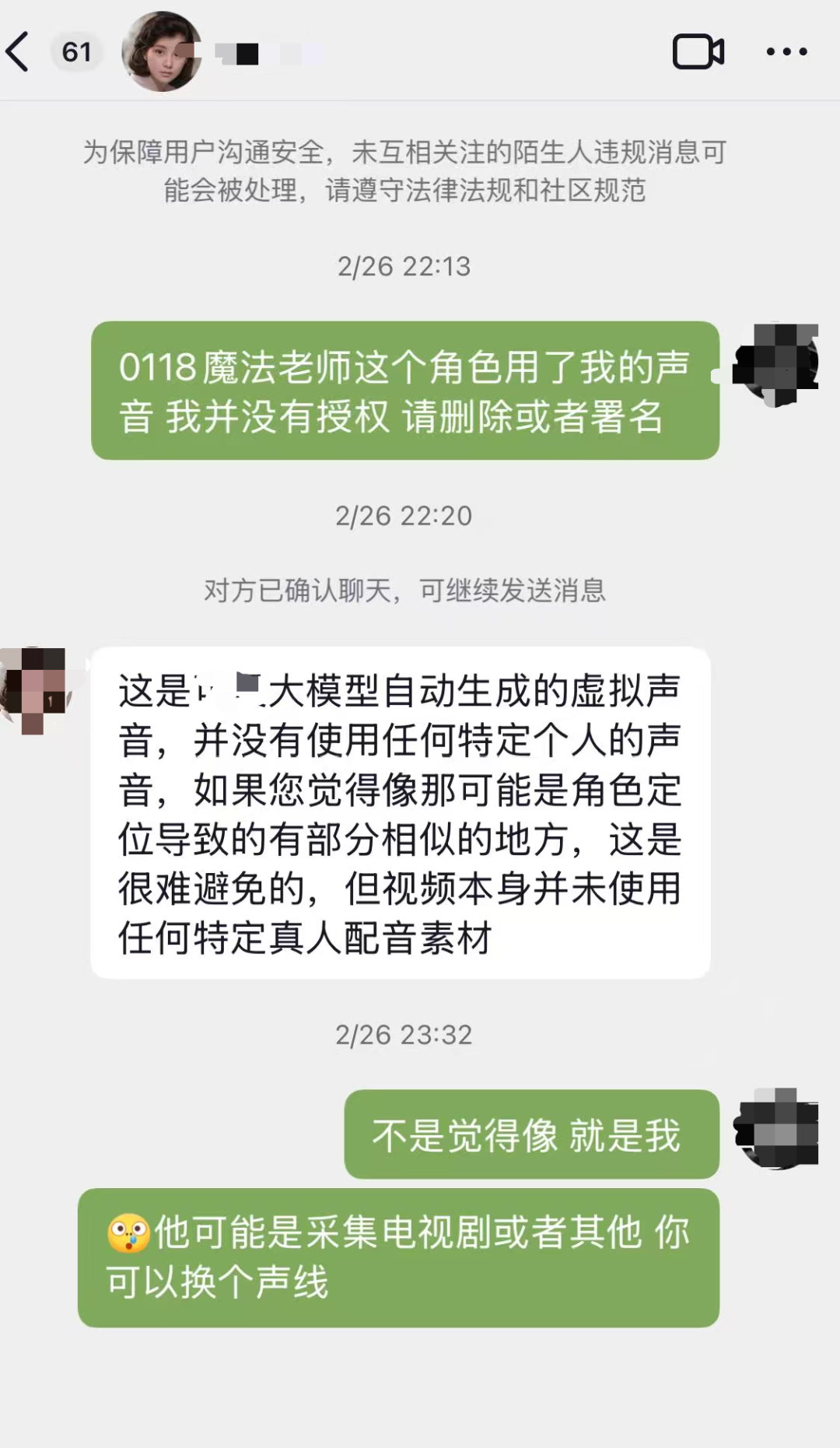
现在,“不承认”成了配音演员们维权时最常遇到的回应。
“他们的话术非常一致。”紫棠说,“他们会说,我的声音是AI生成的,跟你没有关系。如果有相似,那也是AI用别人的素材生成的,你怎么去认定这是你的声音?”
而比起2023年全国首例AI生成声音人格权侵权案,现在的配音演员们面临着更大的维权困境,他们甚至不知道究竟是哪个环节出了问题。
紫棠描述她看到的侵权作品:“一个角色由多个配音员声音拼接而成,第一位配音员说了两句话,就换成第二位配音员,再换为第三位,再换为第四位,再可能再倒回第一位来组成一个角色的配音。”
紫棠和言一都提到,现在他们签合同时,会加入禁止AI授权的条款。言一描述条款内容:“你禁止使用作品当中的声音,用于任何形式的AI采集、训练和生成,仅限于本作品使用。”
但问题是,即使合同里有这一条款,也无法阻止声音被采集。“你无从溯源对方到底采的是哪儿的声音。”紫棠说,“我们不知道是A棚主把我的声音卖了还是B棚主,还是平台直接通过你公开的声音采集的。”
任相雨也接触过不少配音演员的案例咨询,他承认,现在的侵权比殷女士案时“更泛滥”了。
殷女士案中,侵权路径是清晰的:声音从某公司流出,被某平台使用,链条可追溯。但现在,配音演员们不知道自己的声音究竟是从哪里流出去的。况且,一个AI短剧里可能用了十几个配音演员的声音,每个声音可能来自不同的公开作品,被不同的AI模型采集,经过多次混合训练。
任相雨给前来咨询的配音演员的建议是:先自己把被侵权的片段截出来,再用自己的声音把同样的台词录一遍,做个对比样本。如果相似度足够高,再考虑下一步的声纹鉴定。
但声纹鉴定成本极高。“可能得几万块钱。”紫棠说,更麻烦的是,一个配音演员有多个音色,每种音色被侵权,就要单独做一次鉴定。“我的声音越多,我需要花的钱就越多。我最终为了证明我是我自己,要花很多钱。”
任相雨也承认,对于大多数侵权案件,“诉讼是不划算的,一个是时间成本,一个是经济成本。”在现有法律框架下,即使赢了官司,赔偿金额也可能覆盖不了成本。
北京航空航天大学法学院教授、数字正义研究中心执行主任裴炜指出,关于输入端的侵权,在学界充满争议。裴炜解释,有学者认为在未经当事人允许的情况下,大模型就使用其素材进行AI训练也构成侵权,但也有一种声音认为,仅使用声音进行AI训练就构成侵权有待商榷。
但即使在输出端,裴炜对配音演员们的维权也并不乐观,裴炜介绍,可识别性是指一般公众能否通过声音联想到特定自然人。但“一般公众”的标准是什么?是所有人都能识别,还是相关领域的人能识别就行?
这意味着,那些腰部、底部的配音演员,他们的声音在同行业内一耳朵就能认出来,但在公众层面,没人知道他们是谁,他们恰恰处于法律保护的灰色地带。